
Building applications that scale through proper scheduling
 As we transtion to building distributed systems, we need to shed some of the anti-patterns of web application development that we have applied for ages.
The ease of compute access made most of us think that we can process every job interactively, and when things slow down, we just scale by virtue of adding instances. Now when that wasn’t the case, and scaling compute actually meant that a real estate operation was required (AKA “get more room to get more mainframes”) back in the day, we actually had process differentiation. Batch jobs would run on specific time windows when CPU time was available.
As we transtion to building distributed systems, we need to shed some of the anti-patterns of web application development that we have applied for ages.
The ease of compute access made most of us think that we can process every job interactively, and when things slow down, we just scale by virtue of adding instances. Now when that wasn’t the case, and scaling compute actually meant that a real estate operation was required (AKA “get more room to get more mainframes”) back in the day, we actually had process differentiation. Batch jobs would run on specific time windows when CPU time was available.
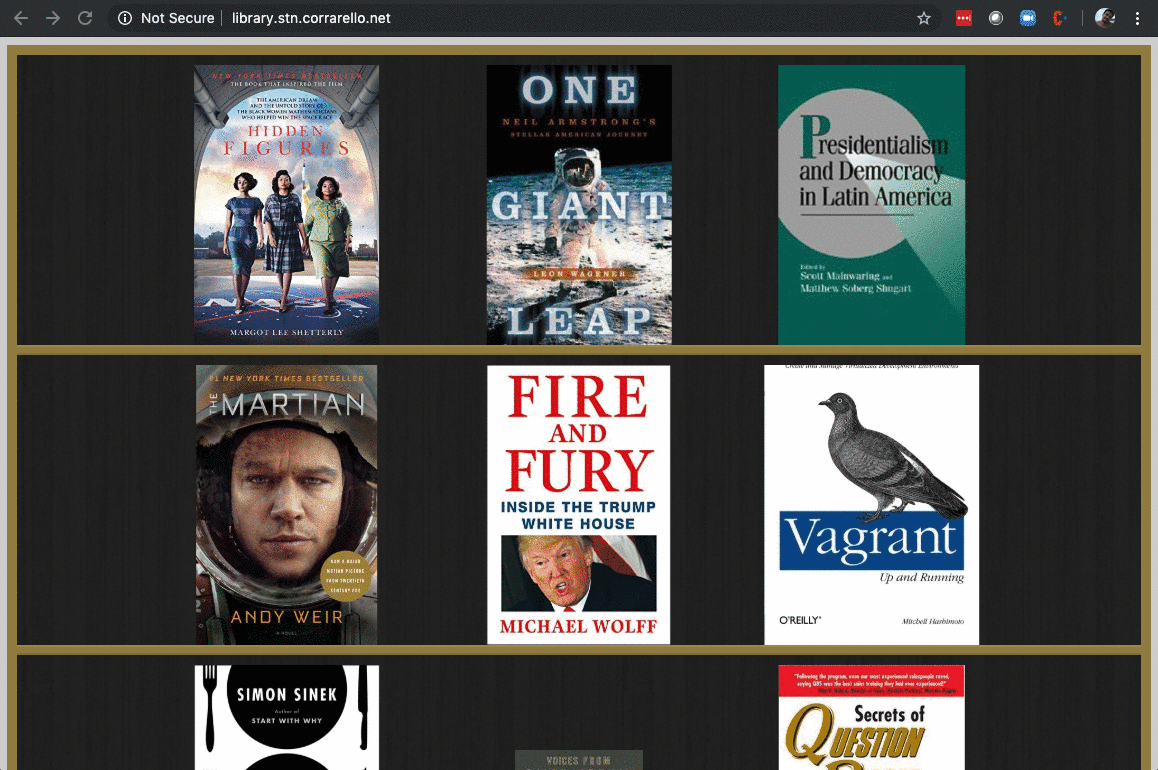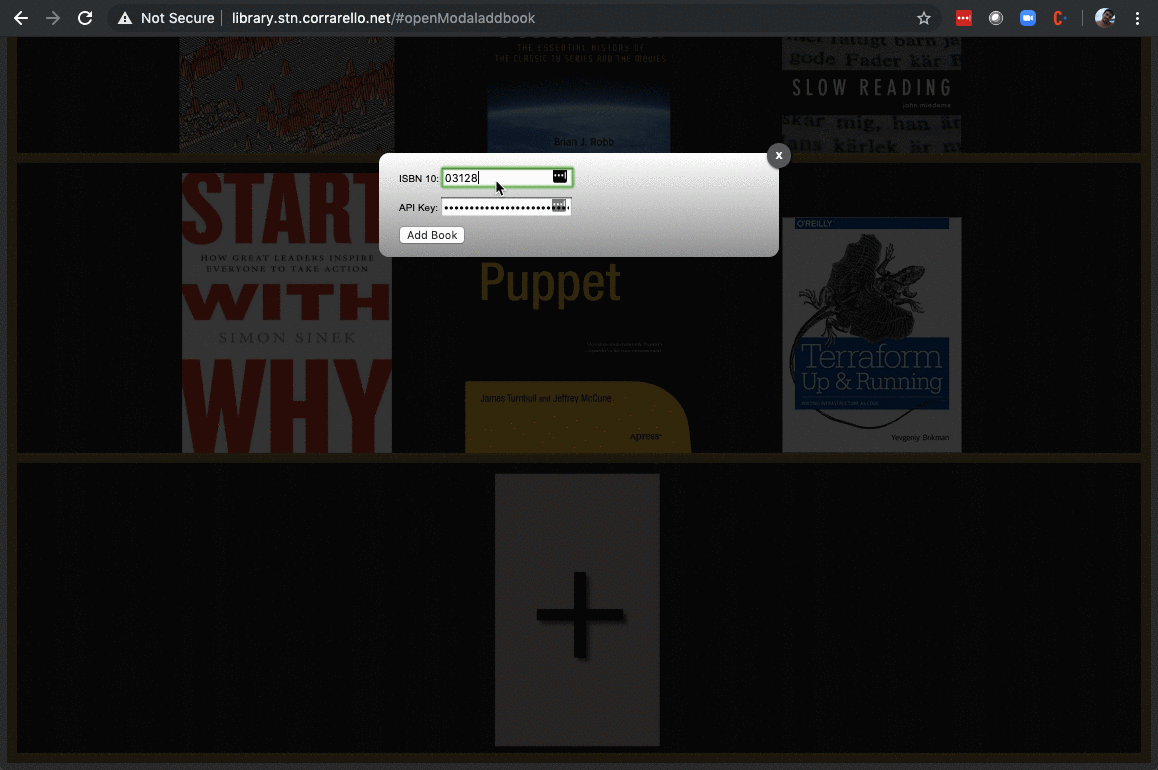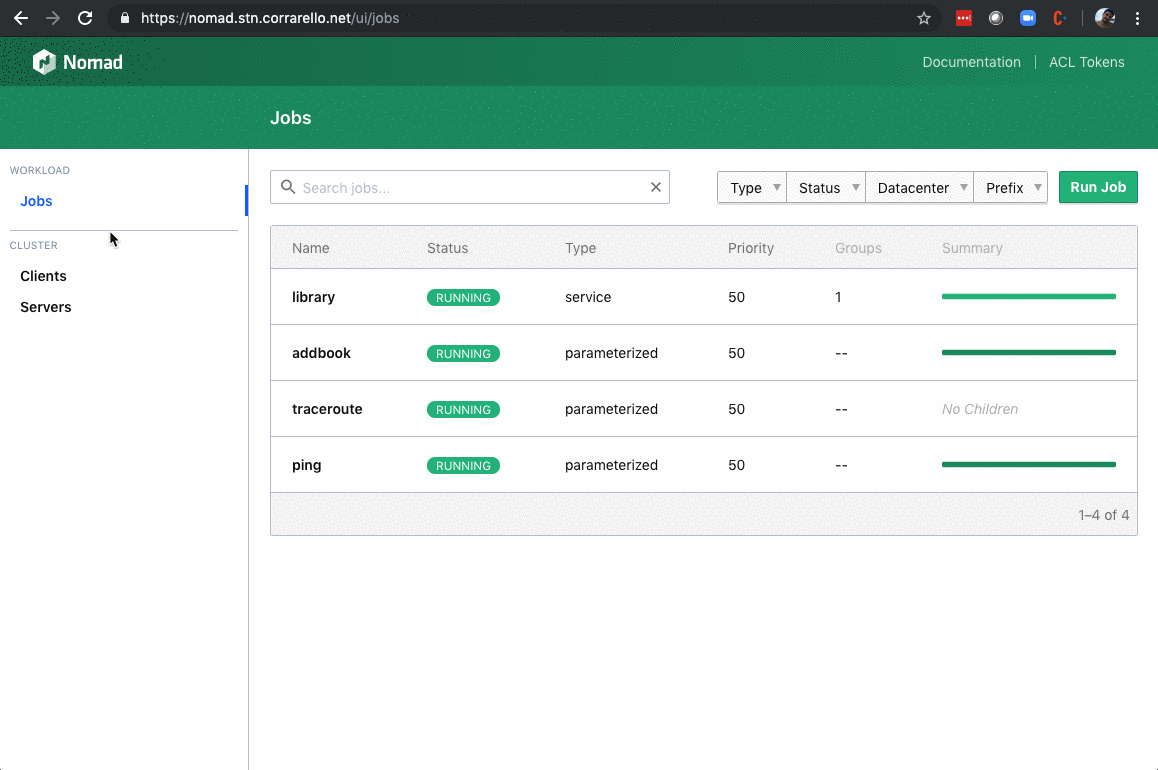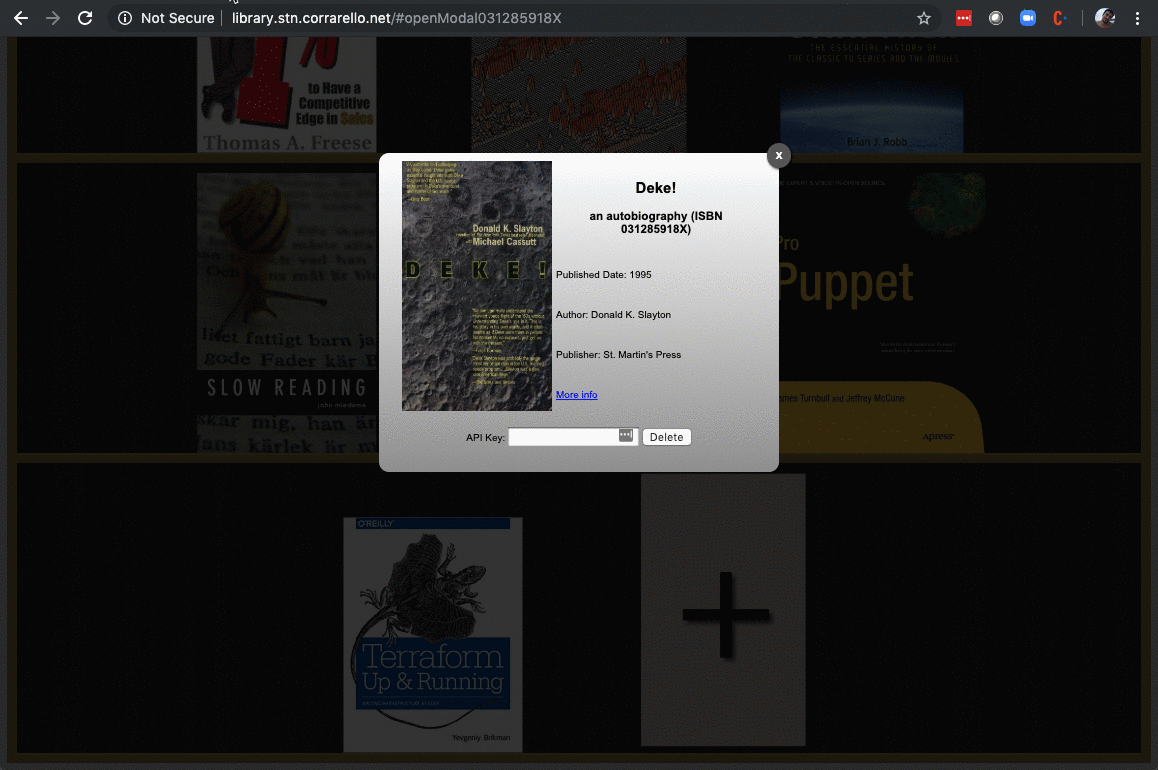
Now traditionally, if your application is super complex, you have most likely been through this. You are probably using a message queue or ESB. This post might not be for you. Now if you are still just piling up code in Rails or Node, there are things that you can probably offload as batch (or in my case, parameterized dispatch, but I’ll explain that later). So here I’ve got this library app that I use at home to keep track of my books, and adding a book is, let’s say, a lot of work.
def create(isbn)
#Check if we got an ISBN
unless isbn.nil?
#Check if the ISBN exists already
if self.by_isbn(isbn)[0] == false
#Try to retrieve it from openlibrary or fail gracefully
begin
uri = URI("https://openlibrary.org/api/books?bibkeys=ISBN:#{isbn}&jscmd=data&format=json")
response = Net::HTTP.get(uri)
rescue
return [false, "Cannot connect to OpenLibrary API"]
end
if response != nil
key, data = JSON.parse(response).first
#Sanitize so much data
unless data.nil?
if data["authors"].nil?
authors = 'Unknown'
else
authors = data["authors"][0]["name"].to_s
end
if data["identifiers"].key? 'isbn_10'
isbnadd = data["identifiers"]["isbn_10"][0]
else
isbnadd = data["identifiers"]["isbn_13"][0]
end
if data.key? 'cover'
if data["cover"].key? 'large'
image = data["cover"]["large"].to_s
else
if data["cover"].key? 'small'
image = data["cover"]["small"].to_s
else
image = "http://104.130.11.24/images/noimage.jpg"
end
end
end
if data.key? 'subtitle'
subtitle = data["subtitle"].to_s
else
subtitle = '-'
end
#Encrypt everything as I'm the tinfoil kind of guy
book = {
"isbn" => isbnadd,
"title" => @vault.encrypt(data["title"].to_s, 'library', 'morbury'),
"thumbnail_url" => @vault.encrypt(image, 'library', 'morbury'),
"subtitle" => @vault.encrypt(subtitle, 'library', 'morbury'),
"url" => @vault.encrypt(data["url"].to_s, 'library', 'morbury'),
"publish_date" => @vault.encrypt(data["publish_date"].to_s, 'library', 'morbury'),
"author" => @vault.encrypt(authors, 'library', 'morbury'),
"publishers" => @vault.encrypt(data["publishers"][0]["name"].to_s, 'library', 'morbury'),
}
#Store in Consul
if Diplomat::Kv.put("library/#{isbn}", book.to_json, { http_addr: ENV['CONSUL_HTTP_ADDR'], dc: "stn", token: @vault.getConsulToken})
return [true, isbn]
else
return [false, "Error storing book with ISBN #{isbn}"]
end
else
return [false, "Book not found in the OpenLibrary API"]
end
else
return [false, "Book not found in the OpenLibrary API"]
end
else
return [false, "ISBN already exist"]
end
else
return [false, "ISBN cannot be empty"]
end
end
Now from a user perspective, sure I’m going to see the spinning wheel for a while, but from a compute perspective, it is even worse as I’m wasting a thread that could be used for interactive traffic. Then again I could spawn a thread in the system, but the Linux scheduler has a somewhat “local” view of the world as it would be expected. So how about a scheduler that has a more global view? Weren’t you all using Kubernetes? Well not me, clearly, but then again this pattern would work with any scheduler.
Nomad has this functionality of dispatching a previously defined job, with an added parameter. So if I wanted to do a “distributed” ping
job "ping" {
region = "uk"
type = "batch"
datacenters = ["dc1"]
parameterized {
payload = "forbidden"
meta_required = ["ADDRESS"]
}
group "ping" {
count = 1
task "ping" {
driver = "exec"
config {
command = "ping"
args = ["-c10", "${NOMAD_META_ADDRESS}"]
}
resources {
cpu = 100 # Mhz
memory = 128 # MB
network {
mbits = 10
}
}
}
}
}and I can dispatch it using the CLI like so:
$ nomad job dispatch -meta ADDRESS=192.168.50.1 ping
Dispatched Job ID = ping/dispatch-1563272947-f0762778
Evaluation ID = 3837a46e
==> Monitoring evaluation "3837a46e"
Evaluation triggered by job "ping/dispatch-1563272947-f0762778"
Allocation "5a261c73" created: node "6c2b39dc", group "ping"
Evaluation status changed: "pending" -> "complete"
==> Evaluation "3837a46e" finished with status "complete"
$And the result would be something like:
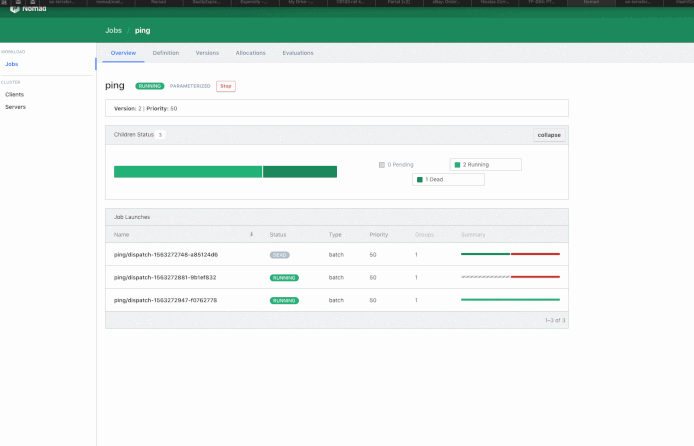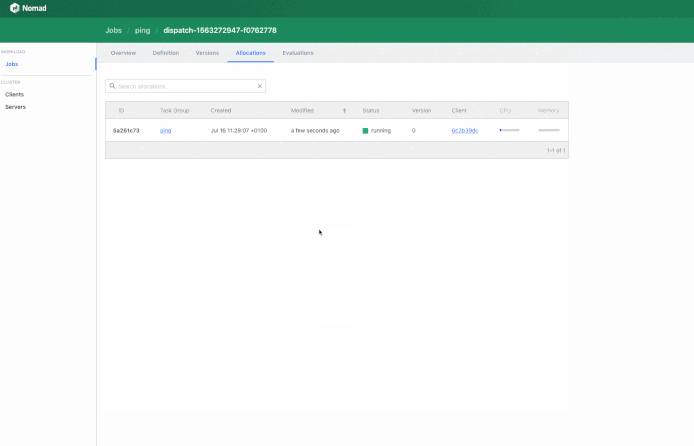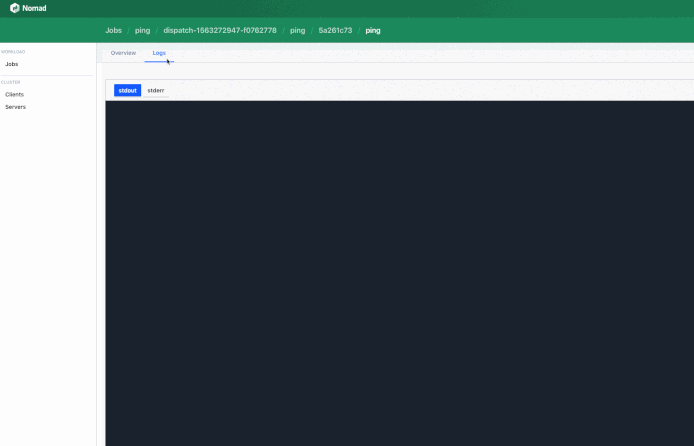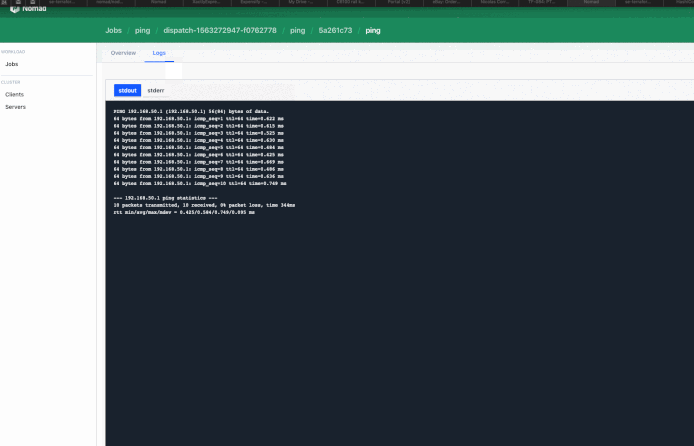
In my case… I’d spawn a Nomad Job upon receiving an API Call:
post '/v1/books/:isbn' do
content_type :json
key = params['key']
if key == @@vault.getAPIKey
payload = {
:Meta => {
:ISBN => params['isbn']
}
}.to_json
if @@books.by_isbn(params['isbn'])[0].to_s == 'false'
dispatchkey = @@vault.getNomadDispatchToken
begin
uri = URI.parse("http://nomad.service.consul:4646/v1/job/addbook/dispatch")
header = {'X-Nomad-Token': dispatchkey}
logger.info "Making request to Nomad to add Book #{params['isbn']}"
http = Net::HTTP.new(uri.host, uri.port)
request = Net::HTTP::Post.new(uri.request_uri, header)
logger.info payload
request.body = payload
response = http.request(request)
success = response.code
logger.info "Nomad's response is #{success}"
rescue
message = [false, "Cannot connect to Nomad"].to_json
status 500, message
end
if success.to_s == '200'
jobstatus = JSON.parse(response.body)
readkey = @@vault.getConsulReadToken
logger.info "Job to add isbn #{params['isbn']} dispatched succesfully"
output = [true, readkey, jobstatus].to_json
status 200
output
else
halt 500, response.body
end
else
halt 500, "Book already exists".to_json
end
else halt 401, "Unauthorized".to_json
end
endAs you can see there I’m getting a Consul Token that I’m passing to the UI (it lasts for a minute) and I’m getting another Nomad token from Vault (which expires in 5 minutes) to do the request.
Final result looks fantastic
About the author: Nicolas Corrarello is the Regional Director for Solutions Engineering @ HashiCorp based out of London.








