
Razor by example
A long long time ago, in a country far away, I wrote the Network Install guide for Fedora describing how to set up a tftp/dhcp server to PXE Boot machines, with a nice menu and all that. At the time, all the cool kids where using Satellite / Spacewalk, or were looking at server MAC Addresses in their CMDB / Inventory. It was published in 2008, I’m not a cool kid anymore, and it looks really outdated (much like my profile in the Fedora Wiki, including a picture from 11 years and 15 kilos ago).
So it’s time to redeem myself in front of all those poor people that have been maintaning /var/lib/tftpboot directories, and dhcpd.conf files. In comes Razor, with a different approach to things. Razor is both a microkernel and a server side component. A bare metal server (or unprovisioned VM) boots this microkernel, collects all the inventory information, and sends it to the server through an API call.
In turn, the server Razor server will evaluate that inventory information against a set of rules, and will provision the server with a base operating system (Linux, Windows, ESXi), and also configure a set of post install tasks (a.k.a. Brokers) in order to hand off the node to a configuration management tool, such as Puppet, or another one related to some culinary aspect.
There is a lot of documentation available on how to set up a Razor server, and I’m not particularly a fan of reinventing the wheel. Of course you need a DHCP Server, (or if you’re into that, you can burn a boot.iso image, though you’ll still need a DHCP server to provide basic network configuration in order for the target server to reach the Razor Sever).
As for which DHCP server to choose, I’m using one bundled with my Mikrotik router, but in a real world example, you’d probably use one bundled on a proper Firewall, or at least ISC DHCPD. Configurating it is far from rocket science:
- If your network booting ROM supports iPXE, the filename is ‘bootstrap.ipxe’, there is also an ‘undionly.kpxe’ image (dhcp option 67, filename in ISC DHCPd).
- Your should set up a tftp server (xinetd, dnsmasq, others) and of course add the parameter to your DHCP server (dhcp option 66, next-server in ISC DHCPd).
Here are a couple of examples lifted from the Razor Server wiki:
# This works for ISC DHCP Server 4.1-ESV-R4 (ubuntu 12.04 LTS default)
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.200 192.168.1.250;
option subnet-mask 255.255.255.0;
if exists user-class and option user-class = "iPXE" {
filename "bootstrap.ipxe";
} else {
filename "undionly.kpxe";
}
next-server 192.168.1.100;
}#This is an example for dnsmasq
dhcp-match=IPXEBOOT,175
dhcp-boot=net:IPXEBOOT,bootstrap.ipxe
dhcp-boot=undionly.kpxe
# TFTP setup
enable-tftp
tftp-root=/var/lib/tftpbootThe PXE image will in turn chainload either the microkernel, or the kernel/initrd of the appropiate Operating System (or Windows Pre-Exectution Environment).
In order to set up your Razor server, I’d advise you to use the packages from the PuppetLabs repository, available in yum.puppetlabs.com (package is called razor-server). Or better yet, just use Puppet to set it up
puppet module install puppetlabs-razor
puppet apply -t -e 'include razor'This will set up the Razor Server in the Puppet Master.
Now it’s time to obtain the PXE images. You can get the ‘undionly.kpxe’ file here, and the bootstrap.ipxe file from the razor server itself. Just curl the contents of http://razor:8080/api/microkernel/bootstrap?nic_max=N to a file, but don’t use localhost, since it actually hardcodes the server name. Drop those two in your tftp home directory.
Technically, your infrastructure is ready to start collecting node information, boot a new node from the network, and hopefully, you’ll see this:
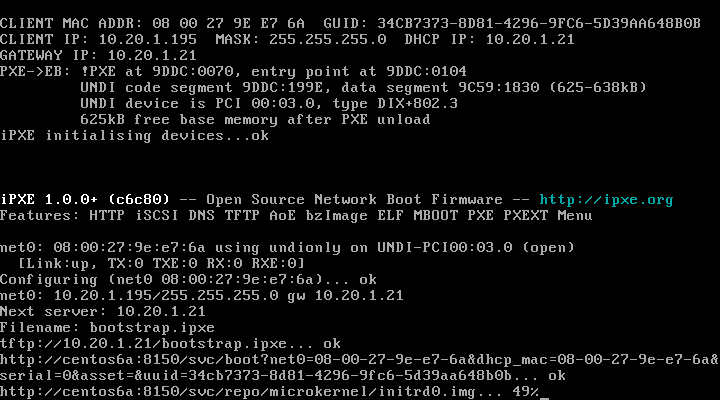
That’s razor booting by the way, give it a couple of minutes (about two in my demo environment) and all your facts about that node will be collected.
So when your node is inventoried, you can issue a ‘razor nodes’ command to see which nodes are ready to be provisioned with razor.
[root@centos6a ~]# razor nodes
From https://localhost:8151/api/collections/nodes:
+-------+-------------------+--------------------+--------+----------------+
| name | dhcp_mac | tags | policy | metadata count |
+-------+-------------------+--------------------+--------+----------------+
| node1 | 08:00:27:27:14:20 | virtual, bigvirtual| --- | 0 |
+-------+-------------------+--------------------+--------+----------------+
| node2 | 08:00:27:46:c3:55 | (none) | --- | 0 |
+-------+-------------------+--------------------+--------+----------------+
| node3 | 08:00:27:9e:e7:6a | (none) | --- | 0 |
+-------+-------------------+--------------------+--------+----------------+
Query an entry by including its name, e.g. `razor nodes node1`Since razor is nice enough to tell us to keep digging, well.. lets!
[root@centos6a ~]# razor nodes node1 hw_info
From https://localhost:8151/api/collections/nodes/node1:
mac: [08-00-27-27-14-20]
Query additional details via: `razor nodes node1 hw_info [mac]`
[root@centos6a ~]# razor nodes node1 facts
From https://localhost:8151/api/collections/nodes/node1:
virtual: virtualbox
is_virtual: true
interfaces: enp0s3,lo
ipaddress_enp0s3: 10.20.1.156
macaddress_enp0s3: 08:00:27:27:14:20
netmask_enp0s3: 255.255.255.0
mtu_enp0s3: 1500
ipaddress_lo: 127.0.0.1
netmask_lo: 255.0.0.0
[..]
blockdevice_sr0_model: CD-ROM
blockdevices: sda,sr0
gid: root
system_uptime:
seconds: 124
hours: 0
days: 0
uptime: 0:02 hours
uniqueid: 007f0100
Query additional details via: `razor nodes node1 facts [dhcp_servers, os, processors, system_uptime]`Now it’s time to get a repository set up. As an example, let’s create one for Centos 6.6
razor create-repo --name centos-6.6 --task centos --iso-url http://mirror.as29550.net/mirror.centos.org/6.6/isos/x86_64/CentOS-6.6-x86_64-bin-DVD1.isoAs you can imagine, this will take a while. Pop up a new shell, and let’s look at brokers in the meanwhile.
Brokers, are basically the way to handover the server to a post-install configuration management tool, (such as Puppet), and also run some post install tasks.
If you want to create your own broker (to set up DNS records maybe?), you can read the official documentation, and other prebuilt brokers are documented in the source tree.
In order to set up a basic broker to handover the server to Puppet Enterprise, create it in the following way:
razor create-broker --name pe --broker-type puppet-pe --configuration server=puppet-master.example.comFinally, we have tags and policies. Tags are applied to server based on ‘rules’ that evaluate ‘facts’.
As a quick example, if you were to create a tag for virtual servers, it would probably look somewhat like this:
[root@centos6a ~]# razor tags
From https://localhost:8151/api/collections/tags:
+--------------+--------------------------------------+-------+----------+
| name | rule | nodes | policies |
+--------------+--------------------------------------+-------+----------+
| virtual | ["=", ["fact", "is_virtual"], true] | 2 | 1 |
+--------------+--------------------------------------+-------+----------+Please take minute here to glance at those amazing tables!. Here’s another example for the official documentation. To create a tag for servers with less than a gig of RAM:
razor create-tag --name small --rule '["<", ["num", ["fact", "memorysize_mb"]], 1024]'Finally, you need to create a Policy. Bare in mind once a policy it’s created, Razor will start provisioning all your nodes as per that policy, so in a brownfield environment, either try to be as specific as possible, or follow these suggestions.
[root@centos6a ~]# razor policies
From https://localhost:8151/api/collections/policies:
+-------------+----------+-------+--------+---------+---------+---------+------+
|name |repo |task | broker | enabled |max_count| tags | nodes|
+-------------+----------+-------+--------+---------+---------+---------+------+
|centos-smvirt|centos-6.6|centos | pe | true |20 | smlvirt | 1 |
+-------------+----------+-------+--------+---------+---------+---------+------+
|win-bigvir |win2012r2 |w2012r2| pe | true |20 | bigvirt | 1 |
+-------------+----------+-------+--------+---------+---------+---------+------+
|centos-virt |centos-6.6|centos | pe | true |20 | virtual | 0 |
+-------------+----------+-------+--------+---------+---------+---------+------+
Query an entry by including its name, e.g. `razor policies centos-for-smallvirtual`Taking into account that it took me a couple of days to write this article, I’d say my technological debt with the community is now settled!.



